
Gulp
快速入门
安装 gulp 命令行工具
npm i gulp-cli -g
在项目中使用 gulp
安装 gulp,作为开发时的依赖项
npm install --save-dev gulp检查 gulp 版本
gulp --version确保输出与下面的屏幕截图匹配,否则你可能需要执行本指南中的上述步骤。
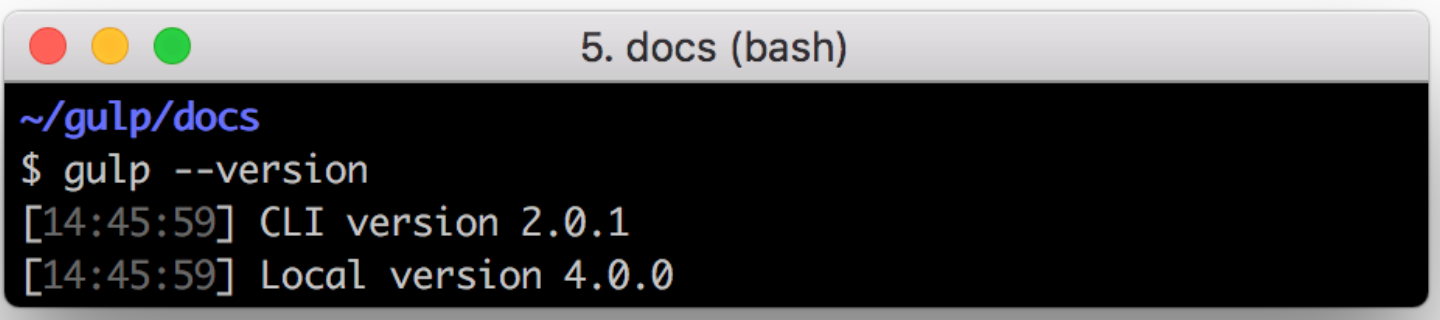
image-20220907085306621 在项目根目录下创建 gulpfile 文件
function defaultTask(cb) { // place code for your default task here cb(); } exports.default = defaultTask在项目根目录下执行 gulp 命令
## exports.default 的命令 gulp ## 运行多个任务 gulp <task> <othertask>控制台输出一下结果,代表执行任务成功
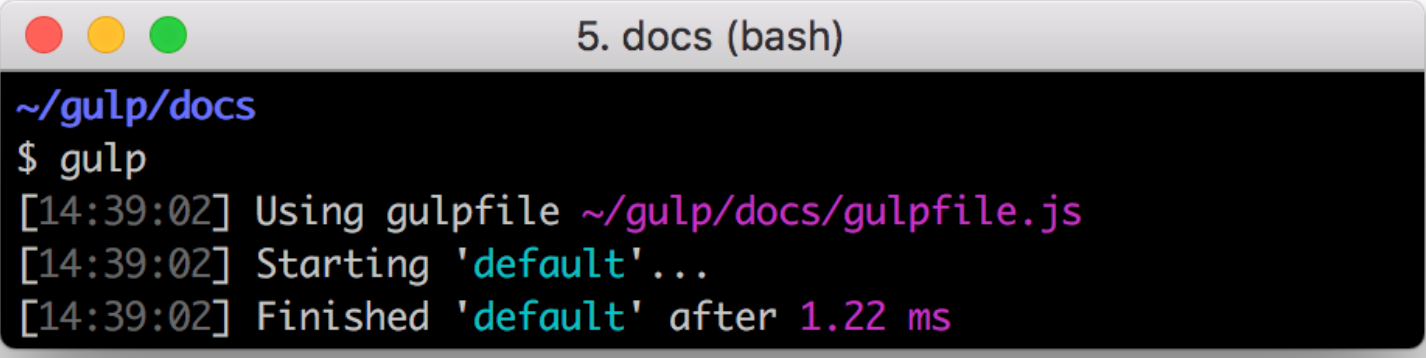
image-20220907090250242
JavaScript 和 Gulpfile
Gulpfile 详解
- 所编写的代码都是纯 JavaScript 代码
- 文件名可以为
gulpfile.js或者Gulpfile.js - Gulpfile 文件在运行
gulp命令时会被自动加载 - 纯 JavaScript 代码或 Node 模块也会被使用
- 任何导出(export)的函数都将注册到 gulp 的任务(task)系统中
Gulpfile 转译
- 可以使用其他语言来编写 gulpfile 文件,比如 ts、babel
- 通过修改
gulpfile.js文件的扩展名来表明所用的编程语言并安装对应的转译模块- 对于 TypeScript,重命名为
gulpfile.ts并安装 ts-node 模块。 - 对于 Babel,重命名为
gulpfile.babel.js并安装 @babel/register 模块
- 对于 TypeScript,重命名为
- 针对此功能的高级知识和已支持的扩展名的完整列表,请参考 gulpfile 转译 文档。
Gulpfile 分割
- 如果 gulpfile 文件过大,可以将其替换为名为
gulpfile.js的目录,该目录中包含了一个名为index.js的文件,该文件被当作gulpfile.js使用。并且,该目录中还可以包含各个独立的任务(task)模块。 - 每个任务(task)可以被分割为独立的文件,然后导入(import)到 gulpfile 文件中并组合。这不仅使事情变得井然有序,而且可以对每个任务(task)进行单独测试,或者根据条件改变组合。
创建任务
- 每个 gulp 任务(task)都是一个异步的 JavaScript 函数
- 此函数是一个可以接收 callback 作为参数的函数,或者是一个返回 stream、promise、event emitter、child process 或 observable类型值的函数
- 由于某些平台的限制而不支持异步任务,因此 gulp 还提供了一个漂亮 替代品
- 在以前的 gulp 版本中,
task()方法用来将函数注册为任务(task)。虽然这个 API 依旧是可以使用的,但是 导出(export)将会是主要的注册机制,除非遇到 export 不起作用的情况。
// 新版
exports.build = done => {
console.log('GodX>loghello gulp',);
done()
}
// 旧版
const gulp = require('gulp');
gulp.task('old', done => {
console.log('GodX>logold',);
done()
})
导出任务
任务分为公开任务或私有任务两种
- 公开任务(Public tasks) 从 gulpfile 中被导出(export),可以通过
gulp命令直接调用。 - 私有任务(Private tasks) 被设计为在内部使用,通常作为
series()或parallel()组合的组成部分。
两种异同
- 私有任务不能被 gulp 命令直接调用
- 私有任务只能在 gulpfile 文件内部使用
- 被 export 导出的函数为公开任务,反之为私有任务
示例
const { series } = require('gulp');
// `clean` 函数并未被导出(export),因此被认为是私有任务(private task)。
// 它仍然可以被用在 `series()` 组合中。
function clean(cb) {
// body omitted
cb();
}
// `build` 函数被导出(export)了,因此它是一个公开任务(public task),并且可以被 `gulp` 命令直接调用。
// 它也仍然可以被用在 `series()` 组合中。
function build(cb) {
// body omitted
cb();
}
exports.build = build;
exports.default = series(clean, build);
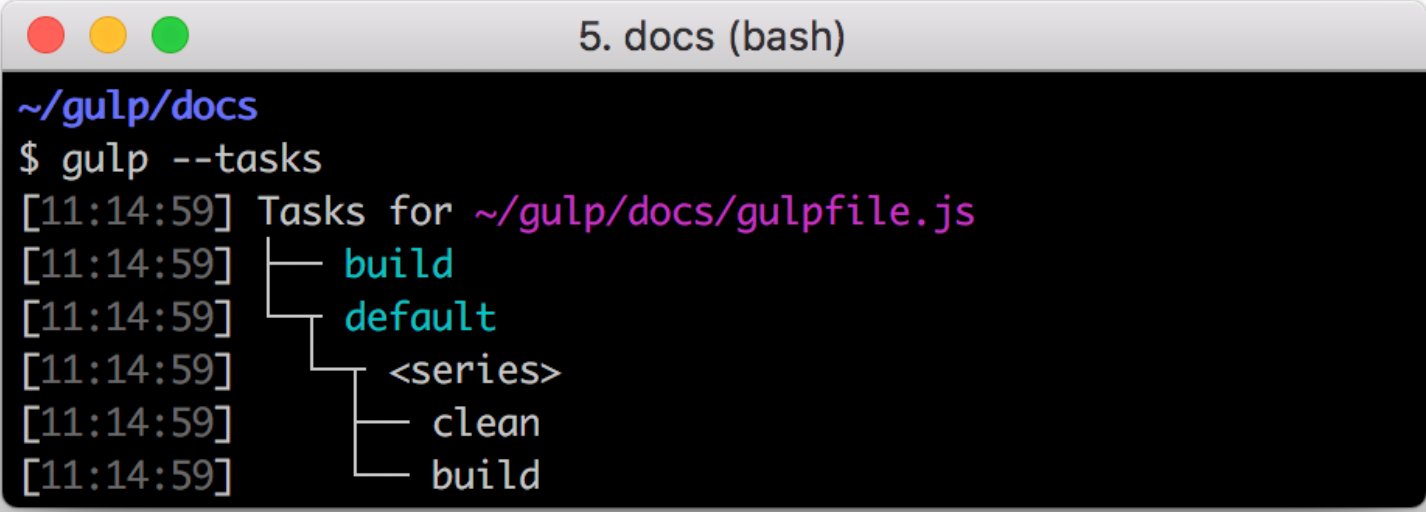
使用 task 命令查看所有任务
gulp --tasks
组合任务
什么是组合任务
- 组合任务允许将多个组合的任务组合为一个更复杂的操作
- 在 gulp 中有两种组合任务的方法方法:
series()和parallel()
两种组合任务的异同
如果需要让任务(task)按顺序执行,请使用
series()方法const { series } = require('gulp'); function transpile(cb) { console.log('GodX>log',1); cb(); } function bundle(cb) { console.log('GodX>log',2); cb(); } exports.default = series(transpile, bundle);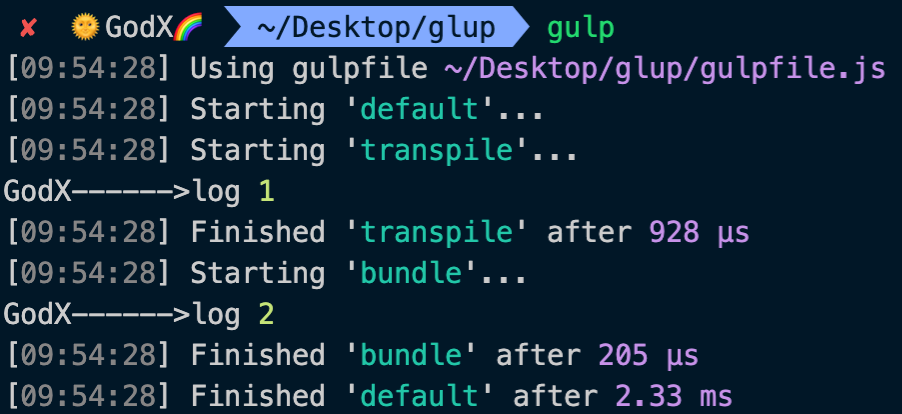
image-20220907095505143 对于希望以最大并发来运行的任务(tasks),可以使用
parallel()方法将它们组合起来。const { parallel } = require('gulp'); function javascript(cb) { setTimeout(() => { console.log('GodX>log',2); },2000) cb(); } function css(cb) { console.log('GodX>log',1); cb(); } exports.default = parallel(javascript, css);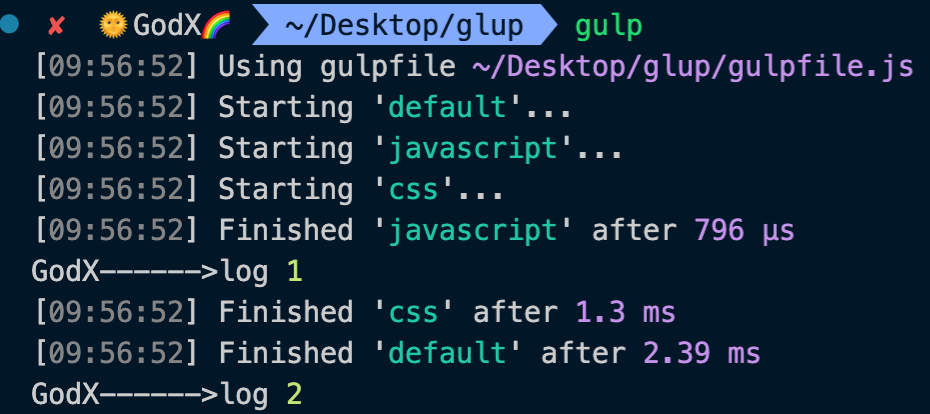
当
series()或parallel()被调用时,任务(tasks)被立即组合在一起。这就允许在组合中进行改变,而不需要在单个任务(task)中进行条件判断。const { series } = require('gulp'); function minify(cb) { // body omitted cb(); } function transpile(cb) { // body omitted cb(); } function livereload(cb) { // body omitted cb(); } if (process.env.NODE_ENV === 'production') { exports.build = series(transpile, minify); } else { exports.build = series(transpile, livereload); }series()和parallel()可以被嵌套到任意深度。const { series, parallel } = require('gulp'); function clean(cb) { // body omitted cb(); } function cssTranspile(cb) { // body omitted cb(); } function cssMinify(cb) { // body omitted cb(); } function jsTranspile(cb) { // body omitted cb(); } function jsBundle(cb) { // body omitted cb(); } function jsMinify(cb) { // body omitted cb(); } function publish(cb) { // body omitted cb(); } exports.build = series( clean, parallel( cssTranspile, series(jsTranspile, jsBundle) ), parallel(cssMinify, jsMinify), publish );当一个组合操作执行时,这个组合中的每一个任务每次被调用时都会被执行。例如,在两个不同的任务(task)之间调用的
clean任务(task)将被执行两次,并且将导致不可预期的结果。因此,最好重构组合中的clean任务(task)。
如果你有如下代码// This is INCORRECT const { series, parallel } = require('gulp'); const clean = function(cb) { // body omitted cb(); }; const css = series(clean, function(cb) { // body omitted cb(); }); const javascript = series(clean, function(cb) { // body omitted cb(); }); exports.build = parallel(css, javascript);可以重构为:
const { series, parallel } = require('gulp'); function clean(cb) { // body omitted cb(); } function css(cb) { // body omitted cb(); } function javascript(cb) { // body omitted cb(); } exports.build = series(clean, parallel(css, javascript));
异步执行
当从任务(task)中返回 stream、promise、event emitter、child process 或 observable 时,成功或错误值将通知 gulp 是否继续执行或结束。如果任务(task)出错,gulp 将立即结束执行并显示该错误
const fs = require('fs')
exports.callback = done => {
console.log('callback task')
done()
}
exports.callback_error = done => {
console.log('callback task')
done(new Error('task failed'))
}
exports.promise = () => {
console.log('promise task')
return Promise.resolve()
}
exports.promise_error = () => {
console.log('promise task')
return Promise.reject(new Error('task failed'))
}
const timeout = time => {
return new Promise(resolve => {
setTimeout(resolve, time)
})
}
exports.async = async () => {
await timeout(1000)
console.log('async task')
}
// exports.stream = () => {
// const read = fs.createReadStream('yarn.lock')
// const write = fs.createWriteStream('a.txt')
// read.pipe(write)
// return read
// }
exports.stream = done => {
const read = fs.createReadStream('yarn.lock')
const write = fs.createWriteStream('a.txt')
read.pipe(write) // 将 yarn.lock 文件中的内容复制到 a.txt 文件中
read.on('end', () => {
done()
})
}
处理文件
- gulp 暴露了
src()和dest()方法用于处理计算机上存放的文件。- src 用来找到你需要处理的流文件
- dest 用来输出处理后的文件流到指定的目录下
src()接受 glob 参数,并从文件系统中读取文件然后生成一个 Node 流(stream)- 它将所有匹配的文件读取到内存中并通过流(stream)进行处理
- 流(stream)所提供的主要的 API 是
.pipe()方法,用于连接转换流(Transform streams)或可写流(Writable streams)- 转换流:将流通过一些插件处理转换成你想要的格式
- 可写流:可以进行操作的流
示例
const { src, dest } = require("gulp");
const uglify = require("gulp-uglify"); // 压缩js
const babel = require("gulp-babel"); // 语法转换
exports.default = () => {
return src("src/index.js")
.pipe(
babel({
presets: ["@babel/preset-env"]
})
)
.pipe(uglify())
.pipe(dest("output/"));
};
向流(stream)中添加文件
src() 也可以放在管道(pipeline)的中间,以根据给定的 glob 向流(stream)中添加文件。新加入的文件只对后续的转换可用。如果 glob 匹配的文件与之前的有重复,仍然会再次添加文件。
这对于在添加普通的 JavaScript 文件之前先转换部分文件的场景很有用,添加新的文件后可以对所有文件统一进行压缩并混淆(uglifying)。
const { src, dest } = require("gulp");
const uglify = require("gulp-uglify");
const babel = require("gulp-babel");
exports.default = () => {
return src("src/index.js")
.pipe(
babel({
presets: ["@babel/preset-env"]
})
)
.pipe(src("test/*.js"))
.pipe(uglify())
.pipe(dest("output/"));
};
分阶段输出
- 可以把 dest()返回的文件流当作处理过的 src()再做新一轮的处理
- 此功能可用于在同一个管道(pipeline)中创建未压缩(unminified)和已压缩(minified)的文件
const { src, dest } = require("gulp");
const uglify = require("gulp-uglify");
const babel = require("gulp-babel");
const rename = require("gulp-rename");
exports.default = () => {
return src("src/index.js")
.pipe(
babel({
presets: ["@babel/preset-env"]
})
)
.pipe(src("test/*.js"))
.pipe(dest("dev/"))
.pipe(uglify())
.pipe(rename({ extname: '.min.js' }))
.pipe(dest("prod/"));
};
模式:流动(streaming)、缓冲(buffered)和空(empty)模式
src() 可以工作在三种模式下:缓冲(buffering)、流动(streaming)和空(empty)模式。这些模式可以通过对 src() 的 buffer 和 read 参数 进行设置。
- 缓冲(Buffering)模式是默认模式,将文件内容加载内存中。插件通常运行在缓冲(buffering)模式下,并且许多插件不支持流动(streaming)模式。
- 流动(Streaming)模式的存在主要用于操作无法放入内存中的大文件,例如巨幅图像或电影。文件内容从文件系统中以小块的方式流式传输,而不是一次性全部加载。如果需要流动(streaming)模式,请查找支持此模式的插件或自己编写。
- 空(Empty)模式不包含任何内容,仅在处理文件元数据时有用。
Glob 详解
- 用于匹配文件路径
- 通常作为 scr 方法的参数传入,用于确定哪些文件需要被操作
- glob 或 glob 数组必须至少匹配到一个匹配项,否则
src()将报错 - 将按照每个 glob 在数组中的位置依次执行匹配 - 这尤其对于取反(negative) glob 有用
字符串片段与分隔符
在 glob 中,分隔符永远是
/字符 - 不区分操作系统在 glob 中,
\\字符被保留作为转义符使用// * 将被作为一个普通字符使用,而不再是通配符了 'glob_with_uncommon_\\*_character.js'由于 Node 使用
\\作为路径分隔符- 不能使用 node 中的 path 类方法来创建 glob
- 还要避免使用
__dirname和__filename全局变量 - 由于同样的原因,
process.cwd()方法也要避免使用
特殊字符: * (一个星号)
- 在一个字符串片段中匹配任意数量的字符,包括零个匹配。
- 对于匹配单级目录下的文件很有用
示例
// 匹配 scripts 目录下所有的 js 文件
'scripts/*.js'
特殊字符: ** (两个星号)
- 在多个字符串片段中匹配任意数量的字符,包括零个匹配。
- 对于匹配嵌套目录下的文件很有用
示例
// 匹配 scripts 目录下所有 js文件
'scripts/**/*.js'
** 会把目录也一起复制
特殊字符: ! (取反)
glob 数组中的取反(negative)glob 必须跟在一个非取反(non-negative)的 glob 后面
第一个 glob 匹配到一组匹配项,然后后面的取反 glob 删除这些匹配项中的一部分
如果取反 glob 只是由普通字符组成的字符串,则执行效率是最高的
// 排除 config 目录下的 js文件 src(["src/**/*.js","!src/config/*.js"])取反(negative) glob 可以作为对带有两个星号的 glob 的限制手段
['**/*.js', '!node_modules/**/*']